今天看了一篇神经网络的文章,作者用11行就实现了一个神经网络,原文地址:A Neural Network in 11 lines of Python (Part 1),深为叹服,翻译如下。
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)。
概要: 直接上手代码是最好的学习方式. 这篇教程通过使用Python语言实现一段非常简单的示例代码来讲解back propagation(BP反向传播算法)算法。
直接上代码:
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1
for j in xrange(60000):
l1 = 1/(1+np.exp(-(np.dot(X,syn0))))
l2 = 1/(1+np.exp(-(np.dot(l1,syn1))))
l2_delta = (y - l2)*(l2*(1-l2))
l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1))
syn1 += l1.T.dot(l2_delta)
syn0 += X.T.dot(l1_delta)
11行代码就实现了一个神经网络....然而,这也是一个过于简洁的神经网络。下面我就将分步讲解这个神经网络的实现,以帮助读者了解并使用BP反向传播算法。
第一部分: 简洁的神经网络
神经网络使用反向传播算法训练输入数据来预测输出数据。
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
观察上表,考虑如何用三个维度的输入数据去预测一个维度的输出。我们可以通过一个简单方法来解决这个问题:测量统计一下输入值与输出值之间的关系。使用这个方法,我们可以发现左边的输入数据与右边的输出数据是紧密相关的。直观意义上讲,BP反向传播算法便是通过这种方式来衡量数据间的统计关系进而得到模型的。下面开始动手实践。
两层的神经网络
import numpy as np
# sigmoid function
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
# input dataset
X = np.array([ [0,0,1],
[0,1,1],
[1,0,1],
[1,1,1] ])
# output dataset
y = np.array([[0,0,1,1]]).T
# seed random numbers to make calculation
# deterministic (just a good practice)
np.random.seed(1)
# initialize weights randomly with mean 0
syn0 = 2*np.random.random((3,1)) - 1
for iter in xrange(10000):
# forward propagation
l0 = X
l1 = nonlin(np.dot(l0,syn0))
# how much did we miss?
l1_error = y - l1
# multiply how much we missed by the
# slope of the sigmoid at the values in l1
l1_delta = l1_error * nonlin(l1,True)
# update weights
syn0 += np.dot(l0.T,l1_delta)
print "Output After Training:"
print l1
输出结果:
Output After Training:
[[ 0.00966449]
[ 0.00786506]
[ 0.99358898]
[ 0.99211957]]
| 变量 | 定义 |
|---|---|
| X | 输入数据集,形式为矩阵,每 1 行代表 1 个训练样本。 |
| y | 输出数据集,形式为矩阵,每 1 行代表 1 个训练样本。 |
| l0 | 网络第 1 层,即网络输入层。 |
| l1 | 网络第 2 层,常称作隐藏层。 |
| syn0 | 第一层权值,突触 0 ,连接 l0 层与 l1 层。 |
| * | 元素相乘,故两等长向量相乘等同于其对等元素分别相乘,结果为同等长度的向量。 |
| - | 元素相减,故两等长向量相减等同于其对等元素分别相减,结果为同等长度的向量。 |
| x.dot(y) | 如果x 和 y 为向量,则进行点积操作;如果均为矩阵,则进行矩阵相乘操作;若其中之一为矩阵,则进行向量与矩阵相乘操作。 |
在"Output After Training"可以看到, 运行成功!!! 在我描述运行过程之前, 建议读者先自己运行一次以有一个对代码运行的直观感受。最好是在ipython notebook中完整跑通代码(自己写脚本也行,但强烈建议notebook). 下面是理解代码的几个关键点:
- 对比l1层在首次迭代和最后一次迭代的状态
- 观察"nonlin" 函数, 正是它将一个概率值作为输出提供给了我们
- 观察l1_error在迭代中是如何变化的
- 将第36行拆开,这里有大部分的秘密武器
- 观察第39行,网络中所有的操作都是在为这步运算作准备
下面,我们一行一行地来分析代码,理解其原理。
建议:用两个屏幕打开这篇文章,这样就能一边阅读代码,一边阅读文章。 撰写博客时我正是这么做的:)。
第1行:导入线性代数工具库numpy, 这也是我们唯一依赖的库。
第4行:这是"非线性"部分. 虽然它可以是许多种函数,但在这里,使用的非线性映射为一个称作 “sigmoid” 的函数(S(x)=1/(1+e-x))。Sigmoid 函数可以将任意数映射到0-1之间. 我们用它将数值转变为概率. 对于神经网络的训练, Sigmoid函数还有其它几个非常不错的特性。
第5行:注意,当deriv=true的时候,这个函数还可以返回sigmoid函数的倒数。 sigmoid函数的优秀特性之一就是只用它的输出值就可以得出它的导数。如果sigmoid函数的输出值为out,那么其导数值为:out*(1-out)。效率非常高。
如果不熟悉导数,可以将导数理解为sigmoid函数在一个给定点上的斜率 (不同的点有不同的斜率)。 想了解更多关于导数的知识,可以参考可汗学院的导数求解过程。
第10行: 这行代码将我们的输入数据集初始化为numpy的矩阵。每一行都是单一的“训练实例” 。每一列都对应着一个输入节点。因此,我们的神经网络有3个输入节点和4个训练实例。
第16行: 这一行初始化我们的输出数据集。在本例中, 我为了节省空间就以水平格式定义了数据集(1行和4列)。".T" 表示转置函数。在转置后, y矩阵就有4行和1列。和输入一样,每一行都是一个训练实例,并且每一列都是一个输出节点。所以,我们的神经网络有3个输入和1个输出。
第20行: 为随机数设定随机种子是一个好习惯。这样一来,我们得到的初始权重集仍然是随机分布的,不过在每次开始训练时,得到的权重初始集分布是完全一致的。这便于我们观察策略变动是如何影响神经网络的训练的。
第23行: 这是神经网络的权重矩阵(可以输出syn0进行观察,syn0=[[-0.16595599],[ 0.44064899],[-0.99977125]],与输入节点数保持一致)。syn0是"synapse zero"的简称,意味着0层突触。因为我们只有2层(输入层和输出层),所以我们只需要一个权重矩阵来连接它们。权重矩阵的维度为(3,1),因为我们有3个输入节点和1个输出节点。换一种方式解释,因为l0层大小为3,l1层大小为1,因为,如果我们想要连接l0和l1,就需要一个维度为(3,1)的中间矩阵。
同时,要注意到随机初始化的权重矩阵均值为0。关于初始化权重,这里面可有不少学问。因为现在我们还只是练习而已,所以在权值初始化时设定均值为0就可以了。
另一个要注意的点是所谓的“神经网络”其实就是指的这一个矩阵。尽管我们有l0层和l1层,但它们只是基于基础数据集的瞬时变化值而已,我们不需要存储它们。在学习训练过程中,只存储syn0。
第25行: 本行开始就是实际的神经网络代码了。for循环迭代式地循环多次执行训练代码,使得我们的网络能更好地拟合训练集。
第28行: 网络第一层l0就是我们的输入数据。接下来详细阐述。输入集X包含4个训练实例,我们同时对所有实例进行处理。这种训练方式被称为“整批”训练。因此,虽然我们有4个不同的l0行,但你可以将其整体视为单个训练实例,这样做并没有什么差别。(我们可以在不改动代码的前提下,一次性装入 1000 个甚至 10000 个实例)。
第29行: 这是神经网络的预测步骤。首先我们让网络根据输入尝试预测输出。然后我们通过观察预测结果作出一些调整,让神经网络下轮迭代中表现得更好一点。
这一行实际上包含两个步骤。首先是l0和syn0两个矩阵相乘;第二部是让我们的输出进入sigmoid函数进行处理。观察矩阵相乘时的维度变化过程:
(4 x 3) dot (3 x 1) = (4 x 1)
矩阵相乘是有约束的,比如等式靠中间的两个维度必须一致。最终产生的矩阵,其行数为第一个矩阵的行数,列数则为第二个矩阵的列数。
因为我们装入了 4 个训练实例,所以最终也得到了 4 个猜测结果,即一个(4 x 1)的矩阵。每一个输出都对应了给定输入下网络对正确结果的一个猜测。这也能直观地解释:为什么我们可以“载入”任意数目的训练实例。在这种情况下,矩阵乘法仍是奏效的。:)
第32行:所以,对于每一输入,l1 都会有对应的一个“猜测”结果。然后将真实的结果y与猜测结果l1作减,就可以对比得到网络预测的效果怎么样。l1_error 是一个有正数和负数组成的向量,它可以反映出网络的误差有多大。
第36行: 干货到了!这里就是秘密武器所在!本行代码信息量比较大,所以将它拆成两部分来分析。
求导
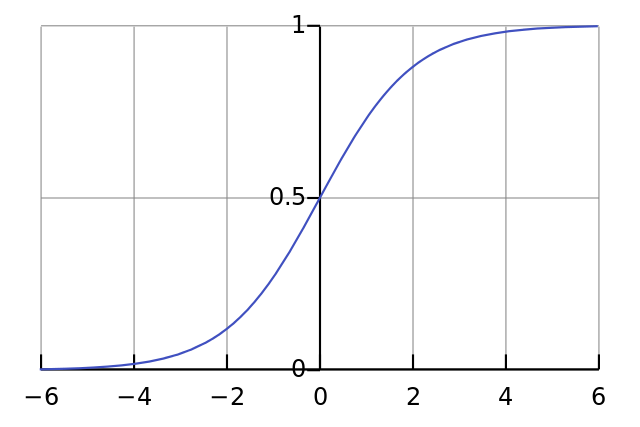
nonlin(l1,True)
如果 l1 可表示成 3 个点,如下图所示,以上代码就可产生下图的三条斜线。注意到,在 x=2.0 处(绿色点)输出值很大时,以及在x=-1.0 处(紫色点)输出值很小时,斜线都非常十分平缓。如你所见,斜度最高的点位于 x=0 处(蓝色点)。这一特性非常重要。另外也可发现,所有的导数值都在 0 到 1 范围之内。
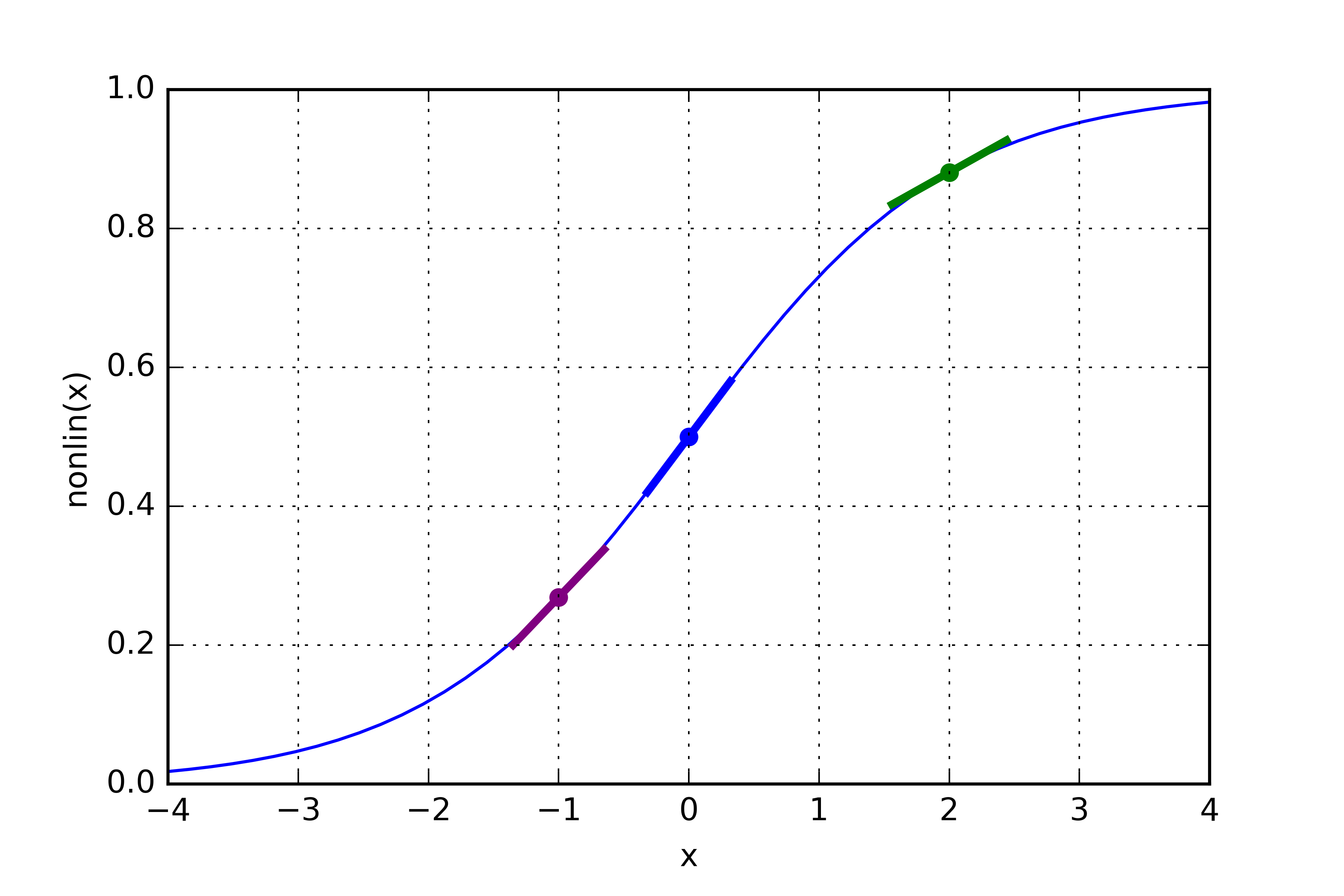
整体认知:误差项加权导数值
l1_delta = l1_error * nonlin(l1,True)
“误差项加权导数值”这个名词在数学上还有更为严谨的描述,但是我觉得这个定义准确地捕捉到了算法的意图。 l1_error 是(4,1)大小的矩阵,nonlin(l1,True)返回的便是(4,1)的矩阵。而我们所做的就是将其“逐元素地”相乘,得到的是一个(4,1)大小的矩阵 l1_delta ,它的每一个元素就是元素相乘的结果。
当我们将“斜率”乘上误差时,实际上就在以高确信度减小预测误差。再看下sigmoid函数曲线图!当斜率非常平缓时(接近于 0时),网络输出要么是一个很大的值,要么是一个很小的值。这就意味着神经网络这时候十分确定是否是这种情况。然而,如果网络的判定结果在(x = 0.5,y = 0.5)附近时,它便不那么确定了。对于这种“似是而非”的预测情形,我们对其做最大的调整,而对确定的情形则不多做处理,乘上一个接近于0的数,则对应的调整量便可忽略不计。
第 39 行:更新网络已准备就绪!下面一起来看下一个简单的训练示例。
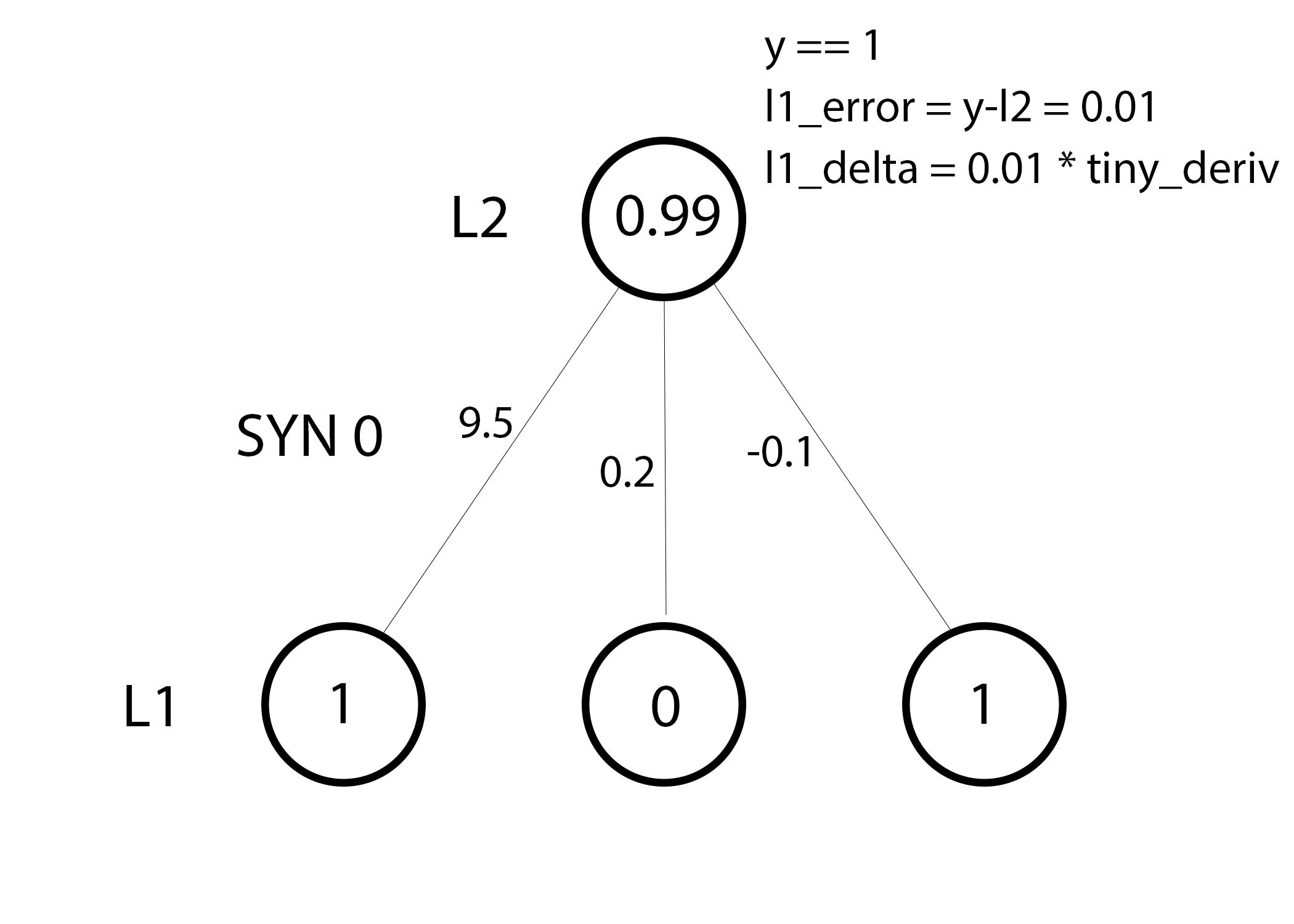
在这个训练示例中,我们已经为权值更新做好了一切准备。下面让我们来更新最左边的权值(9.5)。
权重更新量 = 输入值 * l1_delta
对于最左边的权值,在上式中便是 1.0 乘上 l1_delta 的值。可以想得到,这对权值 9.5 的增量是可以忽略不计的。为什么只有这么小的更新量呢?是因为我们对于预测结果十分确信,而且预测结果有很大把握是正确的。误差和斜率都偏小时,便意味着一个较小的更新量。考虑所有的连接权值,这三个权值的增量都是非常小的。
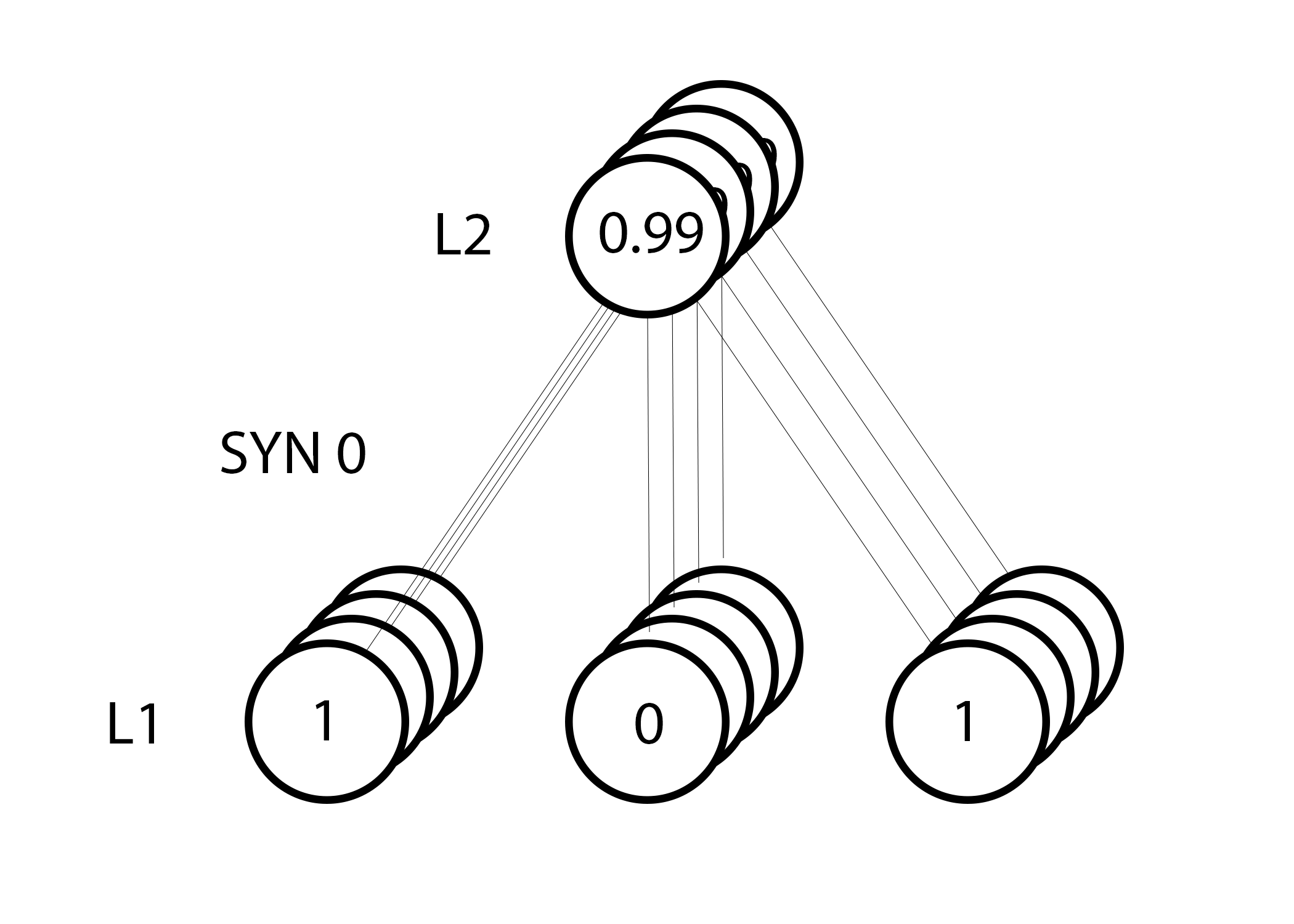
由于采取的是“整批”训练的机制,因此上述更新步骤是在全部的 4 个训练实例上进行的,这看上去也有点类似于图像。那么,第 39 行做了什么事情呢?在这简单的一行代码中,它共完成了下面几个操作:首先计算每一个训练实例中每一个权值对应的权值更新量,再将每个权值的所有更新量累加起来,接着更新这些权值。亲自推导下这个矩阵相乘操作,你便能明白它是如何做到这一点的。
延伸
现在,我们已经知道了神经网络是如何进行更新的。回过头来看看训练数据,作一些深入思考。当输入和输出均为 1 时,我们增加它们间的连接权重;当输入为 1 而输出为 0 时,我们减小其连接权重。
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
因此,在如上 4 个训练示例中,第一个输入结点与输出节点间的权值将持续增大或者保持不变,而其他两个权值在训练过程中表现为同时增大或者减小(忽略中间过程)。这种现象便使得网络能够基于输入与输出间的联系进行学习。
第二部分:一个稍显复杂的问题
| Inputs | Output | ||
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
考虑在给定前两列输入的情况下去尝试预测输出列。关键点在于这两列与输出不存在任何关联,每一列都有 50% 的几率预测结果为 1 ,也有 50% 的几率预测为 0 。
那现在的输出模式是怎样呢?看起来好像和第三列毫不相关,其值始终为 1 。而第 1 列和第 2 列却可以提供更多信息:当其中 1 列值为1(但不同时为 1 !)时,输出便为1 。这便是我们要找的模式!
以上可以视为一种“非线性”模式,因为单个输入与输出间不存在一个一对一的关系。而输入的组合与输出间存在着一对一的关系,在这里也就是第1列和第2列的组合。

图像识别也是类似的问题。如果有 100 张尺寸相同的烟斗图片和脚踏车图片,那么,不存在单个像素点位置能够直接说明某张图片是脚踏车还是烟斗。单纯从统计角度来看,这些像素可能也是随机分布的。然而,某些像素的组合却不是随机的,也就是说,正是这种组合才形成了一辆脚踏车或者是一个人。
我们的策略
由上述可知,像素组合后的产物与输出存在着一对一的关系。为了先完成这种组合,我们需要额外增加一个网络层。第一层对输入进行组合,然后以第一层的输出作为输入,通过第二层的映射得到最终的输出结果。在给出具体实现之前,先来看下这张表格。
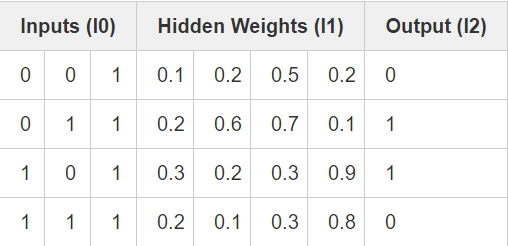
随机初始化权重后,我们便得到了第1层的隐态值。注意到了吗?第二列(第二个隐层结点)已经同输出有一定的相关度了!虽不是十分完美,但却的确存在了。寻找这种相关性在神经网络训练中占了很大比重。甚至可以认定,这也是训练神经网络的唯一途径。随后的训练中,我们要做的便是将这种关联进一步增大。syn1 权值矩阵将隐层的组合输出映射到最终结果,而在更新 syn1 的同时,还需要更新 syn0 权值矩阵,以从输入数据中更好地产生这些组合。
注释:通过增加更多的中间层,以对更多关系的组合进行建模。这一策略正是广为人们所熟知的“深度学习”,因为其正是通过不断增加更深的网络层来建模的。
3层神经网络
import numpy as np
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0],
[1],
[1],
[0]])
np.random.seed(1)
# randomly initialize our weights with mean 0
syn0 = 2*np.random.random((3,4)) - 1
syn1 = 2*np.random.random((4,1)) - 1
for j in xrange(60000):
# Feed forward through layers 0, 1, and 2
l0 = X
l1 = nonlin(np.dot(l0,syn0))
l2 = nonlin(np.dot(l1,syn1))
# how much did we miss the target value?
l2_error = y - l2
if (j% 10000) == 0:
print "Error:" + str(np.mean(np.abs(l2_error)))
# in what direction is the target value?
# were we really sure? if so, don't change too much.
l2_delta = l2_error*nonlin(l2,deriv=True)
# how much did each l1 value contribute to the l2 error (according to the weights)?
l1_error = l2_delta.dot(syn1.T)
# in what direction is the target l1?
# were we really sure? if so, don't change too much.
l1_delta = l1_error * nonlin(l1,deriv=True)
syn1 += l1.T.dot(l2_delta)
syn0 += l0.T.dot(l1_delta)
一切看起来都非常熟悉!这只是用这样两个先前的实现相互堆叠而成的,第一层(l1)的输出就是第二层的输入。唯一所出现的新事物便是第43行代码。
第43行:通过对l2层的误差进行“置信度加权”,构建l1层相应的误差。为了做到这点,只要简单的通过l2与l1间的连接权值来传递误差。这种做法也可称作“贡献度加权误差”,因为我们学习的是,l1层每一个结点的输出值对l2层节点误差的贡献程度有多大。接着,用之前2层神经网络实现中的相同步骤,对syn0权值矩阵进行更新。
欢迎关注我的微信公众号:金融与人工智能
